Statistische AI Tipps: Wissenschaftliche Prognosen
Sportvorhersagen
Ladevorgang...
Ladevorgang...

Es gibt zwei Arten von Fußballfans. Die einen verlassen sich auf ihr Bauchgefühl, schauen sich die Tabelle an, erinnern sich an das letzte Spiel und treffen ihre Entscheidung in Sekunden. Die anderen öffnen Tabellenkalkulationen, vergleichen Expected-Goals-Werte, berechnen Wahrscheinlichkeiten und kommen erst nach gründlicher Analyse zu einem Schluss. Beide Gruppen können richtig liegen, beide können falsch liegen. Aber auf lange Sicht hat die zweite Gruppe einen entscheidenden Vorteil: Sie weiß, warum sie richtig oder falsch lag, und kann daraus lernen. Verlasse dich auf harte Fakten und Zahlen mit unseren AI Fussballtipps.
Die statistische Analyse von Fußball hat in den letzten zwei Jahrzehnten eine bemerkenswerte Entwicklung durchgemacht. Was einst das Hobby einiger Mathematiker war, ist heute ein Milliardengeschäft. Die großen Vereine beschäftigen ganze Abteilungen von Datenanalysten, die Buchmacher investieren Millionen in ihre Prognosemodelle, und selbst der interessierte Laie kann auf Datenbanken zugreifen, die vor wenigen Jahren nur Profis vorbehalten waren.
Dieser Artikel erklärt die statistischen Grundlagen, die hinter modernen KI-Fußballtipps stehen. Er zeigt, welche Methoden verwendet werden, wie sie funktionieren und wo ihre Grenzen liegen. Denn wer die Statistik versteht, kann die Prognosen besser einordnen und fundiertere Entscheidungen treffen.
Die Revolution der Daten im Fußball
Die Geschichte der statistischen Fußballanalyse ist eng mit der Geschichte der Datenerfassung verbunden. Lange Zeit beschränkten sich die verfügbaren Statistiken auf das Offensichtliche: Tore, Torschüsse, Ecken, Fouls. Diese Zahlen wurden von Hand erfasst und in Zeitungen veröffentlicht, aber sie sagten wenig über das tatsächliche Spielgeschehen aus. Ein Torschuss konnte ein verzweifelter Versuch aus 30 Metern sein oder eine hundertprozentige Chance aus fünf Metern. Die Statistik unterschied nicht.
Der Durchbruch kam mit der Tracking-Technologie. Moderne Stadien sind mit Kamerasystemen ausgestattet, die jeden Spieler und den Ball mehrmals pro Sekunde erfassen. Aus diesen Rohdaten entstehen detaillierte Bewegungsprofile: Wo stand jeder Spieler zu jedem Zeitpunkt? Wie schnell hat er sich bewegt? In welche Richtung? Diese Informationen ermöglichen eine völlig neue Art der Analyse.
Die Ereignisdaten ergänzen die Positionsdaten. Spezialisierte Unternehmen wie Opta oder StatsBomb erfassen jeden Pass, jeden Zweikampf, jeden Schuss mit allen relevanten Details. Woher kam der Pass? Wohin ging er? Unter welchem Druck stand der Passgeber? War der Empfänger in Bewegung? Diese Fragen können heute für jedes Spiel in den großen Ligen beantwortet werden.
Die Menge der verfügbaren Daten ist beeindruckend. Ein einzelnes Bundesliga-Spiel generiert etwa 3,6 Millionen Datenpunkte, wenn man alle Positionsinformationen mitzählt. Über eine Saison summiert sich das zu Milliarden von Datenpunkten, und über mehrere Jahre und Ligen hinweg wird der Datenberg praktisch unüberschaubar. Kein Mensch kann diese Informationen manuell verarbeiten. Hier kommt die Statistik ins Spiel, und hier zeigt die KI ihre Stärken.
Wahrscheinlichkeitstheorie und Fußball
Das Fundament jeder statistischen Prognose ist die Wahrscheinlichkeitstheorie. Sie liefert die mathematischen Werkzeuge, um Unsicherheit zu quantifizieren und rationale Entscheidungen unter Ungewissheit zu treffen.
Im Fußball ist Unsicherheit allgegenwärtig. Selbst wenn eine Mannschaft klar überlegen ist, kann sie verlieren. Selbst wenn ein Schuss aus bester Position kommt, kann er danebengehen. Die Wahrscheinlichkeitstheorie erlaubt es, diese Unsicherheit in Zahlen zu fassen. Statt zu sagen, dass Bayern München gegen einen Aufsteiger gewinnen wird, sagt man, dass Bayern mit einer Wahrscheinlichkeit von 75 Prozent gewinnt. Wir liefern dir zu jeder Partie auch präzise Tipps mit Wahrscheinlichkeit für alle Ausgänge. Das ist präziser und ehrlicher.
Die Berechnung solcher Wahrscheinlichkeiten basiert auf historischen Daten. Wenn in der Vergangenheit Teams mit ähnlichen Charakteristiken in ähnlichen Situationen aufeinandertrafen, wie oft hat dann das stärkere Team gewonnen? Diese Frage lässt sich mit genügend Daten beantworten, und die Antwort liefert eine Schätzung der Wahrscheinlichkeit für das aktuelle Spiel.
Ein wichtiges Konzept ist die Regression zur Mitte. In jeder Stichprobe gibt es Ausreißer, also Werte, die deutlich vom Durchschnitt abweichen. Diese Ausreißer neigen dazu, sich bei wiederholter Messung dem Durchschnitt anzunähern. Im Fußball bedeutet das: Eine Mannschaft, die in den letzten fünf Spielen deutlich über ihrem Niveau performt hat, wird wahrscheinlich wieder auf ihr normales Niveau zurückfallen. Umgekehrt gilt das auch für Mannschaften in einer Schwächephase. Gute statistische Modelle berücksichtigen diesen Effekt und lassen sich nicht von kurzfristigen Ausreißern täuschen.
Die Konfidenzintervalle sind ein weiteres wichtiges Konzept. Wenn ein Modell vorhersagt, dass eine Mannschaft mit 60 Prozent Wahrscheinlichkeit gewinnt, wie sicher ist diese Schätzung? Ein Konfidenzintervall gibt an, in welchem Bereich der wahre Wert mit einer bestimmten Wahrscheinlichkeit liegt. Ein breites Konfidenzintervall bedeutet große Unsicherheit, ein schmales bedeutet höhere Sicherheit. Bei Fußballprognosen sind die Konfidenzintervalle typischerweise recht breit, was die fundamentale Unsicherheit des Sports widerspiegelt.
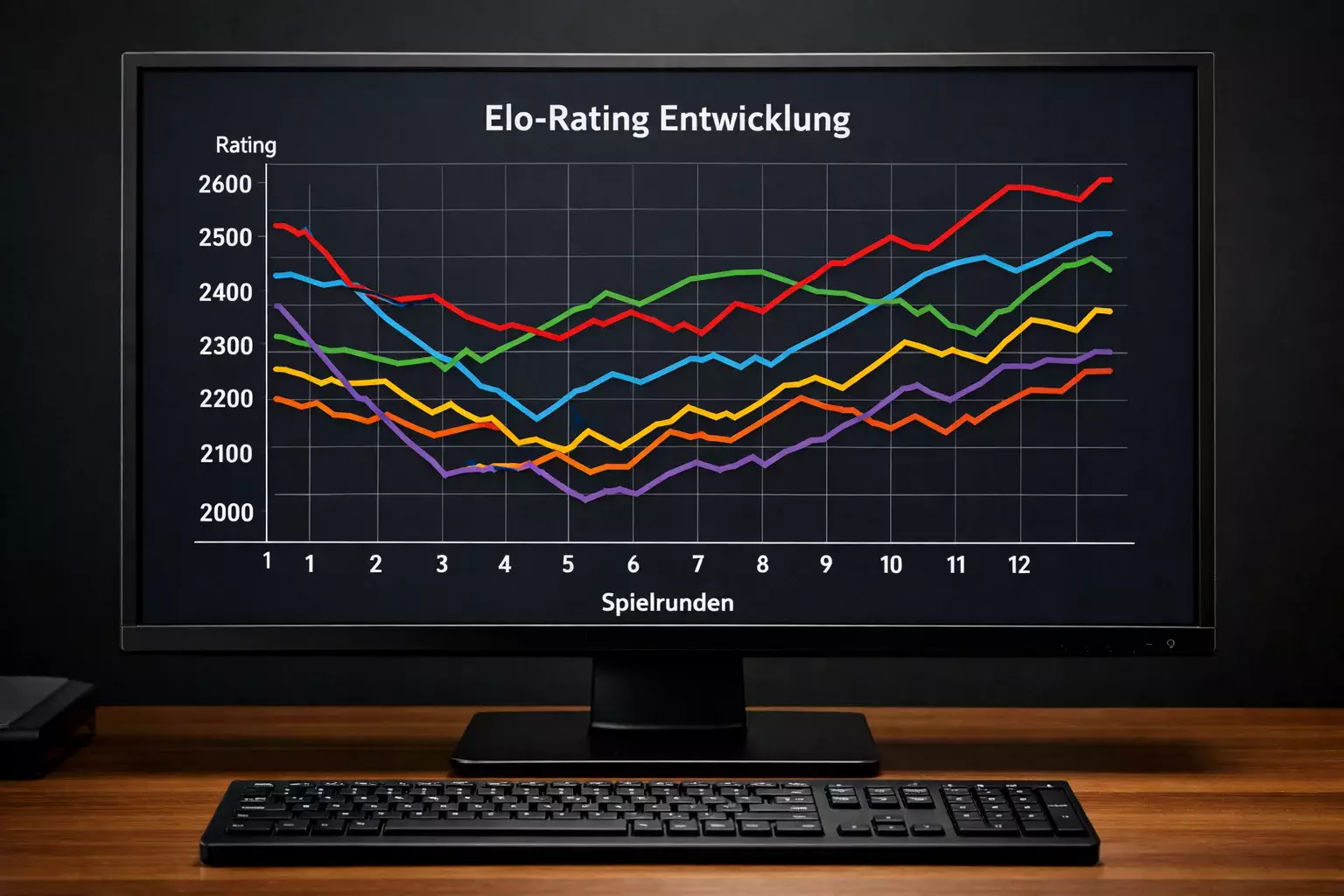
Das Elo-Rating: Einfach und effektiv
Das Elo-Rating ist eines der ältesten und am weitesten verbreiteten Systeme zur Bewertung von Mannschaftsstärken. Ursprünglich für Schach entwickelt, wurde es in den letzten Jahrzehnten auf zahlreiche Sportarten übertragen, darunter auch Fußball.
Die Grundidee ist bestechend einfach. Jede Mannschaft hat einen Punktwert, der ihre Stärke repräsentiert. Nach jedem Spiel werden die Punktwerte angepasst: Der Sieger gewinnt Punkte, der Verlierer verliert Punkte. Die Höhe der Anpassung hängt davon ab, wie überraschend das Ergebnis war. Wenn ein hoch bewertetes Team gegen ein niedrig bewertetes gewinnt, ändern sich die Punktwerte kaum. Wenn aber der Außenseiter gewinnt, gibt es eine deutliche Verschiebung.
Die Stärke des Elo-Systems liegt in seiner Selbstkorrektur. Wenn eine Mannschaft unterschätzt wird, gewinnt sie häufiger als erwartet und sammelt Punkte, bis ihr Rating ihre wahre Stärke widerspiegelt. Wenn sie überschätzt wird, verliert sie häufiger und fällt im Rating zurück. Über viele Spiele hinweg konvergiert das System zu einer akkuraten Einschätzung.
Für Prognosen ist das Elo-Rating direkt nutzbar. Aus der Differenz der Elo-Werte zweier Mannschaften lässt sich eine Siegwahrscheinlichkeit berechnen. Je größer die Differenz, desto höher die Wahrscheinlichkeit für den Favoriten. Die genaue Formel ist mathematisch wohldefiniert und liefert konsistente Ergebnisse.
Die Grenzen des Elo-Systems liegen in seiner Einfachheit. Es berücksichtigt nur das Endergebnis, nicht den Spielverlauf. Ein 1:0-Sieg nach dominanter Vorstellung zählt genauso viel wie ein glücklicher 1:0-Erfolg gegen den Spielverlauf. Moderne Systeme erweitern das klassische Elo daher um zusätzliche Faktoren wie Tordifferenz, Expected Goals oder Heimvorteil.
Die Poisson-Verteilung für Torprognosen
Die Poisson-Verteilung ist das mathematische Herzstück vieler Fußballprognosemodelle. Sie beschreibt die Wahrscheinlichkeit, dass ein seltenes Ereignis eine bestimmte Anzahl von Malen eintritt, wenn die durchschnittliche Häufigkeit bekannt ist.
Tore im Fußball passen gut zu diesem Modell. In einem typischen Bundesliga-Spiel fallen etwa 2,8 Tore im Durchschnitt. Die Poisson-Verteilung kann vorhersagen, wie wahrscheinlich es ist, dass genau 0, 1, 2, 3 oder mehr Tore fallen. Die Ergebnisse entsprechen erstaunlich gut den empirischen Beobachtungen.
Für die Spielprognose wird die Poisson-Verteilung auf jede Mannschaft einzeln angewendet. Wenn Mannschaft A im Durchschnitt 1,8 Tore pro Spiel erzielt und Mannschaft B 1,0 Tore, können die Wahrscheinlichkeiten für jedes mögliche Ergebnis berechnet werden. Die Wahrscheinlichkeit für ein 2:1 ergibt sich aus der Wahrscheinlichkeit, dass A genau 2 Tore erzielt, multipliziert mit der Wahrscheinlichkeit, dass B genau 1 Tor erzielt.
Die Parameter der Poisson-Verteilung, also die erwarteten Torzahlen, werden aus historischen Daten geschätzt. Dabei fließen verschiedene Faktoren ein: die allgemeine Stärke beider Mannschaften, der Heimvorteil, die aktuelle Form, die spezifische Qualität von Angriff und Abwehr. Je besser diese Parameter geschätzt werden, desto genauer sind die resultierenden Prognosen.
Eine wichtige Erweiterung ist die Berücksichtigung der Korrelation zwischen den Torzahlen beider Mannschaften. In der einfachen Poisson-Annahme sind die Tore unabhängig voneinander. In der Realität stimmt das nicht ganz: Wenn eine Mannschaft früh in Führung geht, verändert sich die Spieldynamik. Die führende Mannschaft kann sich zurückziehen, die zurückliegende muss Risiken eingehen. Fortgeschrittene Modelle berücksichtigen diese Abhängigkeiten.
Bayessche Methoden für bessere Schätzungen
Die bayessche Statistik bietet einen eleganten Rahmen, um Vorwissen mit neuen Daten zu kombinieren. Sie ist besonders nützlich, wenn die Datenlage unsicher ist oder wenn verschiedene Informationsquellen integriert werden sollen.
Der Grundgedanke ist einfach: Man beginnt mit einer Vorannahme über die Wahrscheinlichkeitsverteilung eines Parameters. Diese Vorannahme, der sogenannte Prior, kann auf Expertenwissen, allgemeinen Prinzipien oder früheren Analysen basieren. Dann beobachtet man Daten und aktualisiert die Vorannahme entsprechend. Das Ergebnis ist der Posterior, eine verbesserte Schätzung, die sowohl das Vorwissen als auch die neuen Daten berücksichtigt.
Im Fußball ist dieser Ansatz besonders wertvoll zu Saisonbeginn. Nach nur zwei oder drei Spieltagen sind die Ergebnisse noch stark vom Zufall geprägt. Ein reiner Durchschnitt über die bisherigen Spiele wäre instabil und unzuverlässig. Ein bayessches Modell kann das Vorwissen aus der letzten Saison als Prior nutzen und dieses schrittweise an die neuen Ergebnisse anpassen. Das Resultat ist eine stabilere Schätzung, die weniger von einzelnen Ausreißern beeinflusst wird.
Ein weiterer Vorteil bayesscher Methoden ist die natürliche Quantifizierung von Unsicherheit. Der Posterior ist keine einzelne Zahl, sondern eine Verteilung. Aus dieser Verteilung können Konfidenzintervalle, Wahrscheinlichkeiten für bestimmte Szenarien und Risikomaße direkt abgelesen werden. Diese Information ist für Wettentscheidungen wertvoll, weil sie zeigt, wie sicher oder unsicher eine Prognose ist.
Die Nachteile bayesscher Methoden liegen im höheren Rechenaufwand und in der Notwendigkeit, geeignete Priors zu wählen. Ein schlecht gewählter Prior kann die Ergebnisse verzerren, insbesondere wenn wenige Daten vorliegen. In der Praxis erfordert die Anwendung daher einige Erfahrung und Sorgfalt.
Big Data und maschinelles Lernen
Die Verfügbarkeit großer Datenmengen hat den Einsatz maschineller Lernverfahren im Fußball ermöglicht. Diese Methoden können komplexe Muster in den Daten erkennen, die für Menschen unsichtbar bleiben würden.
Random Forests sind ein populärer Ansatz. Sie kombinieren viele einfache Entscheidungsbäume zu einem leistungsfähigen Ensemble. Jeder Baum wird auf einer zufälligen Teilmenge der Daten trainiert und trifft seine eigene Vorhersage. Die Gesamtvorhersage ergibt sich als Durchschnitt oder Mehrheitsentscheidung aller Bäume. Diese Methode ist robust gegenüber Ausreißern und kann nichtlineare Zusammenhänge erfassen.
Neuronale Netze gehen noch einen Schritt weiter. Sie bestehen aus vielen miteinander verbundenen Knoten, die in Schichten organisiert sind. Durch Training auf historischen Daten lernen sie, aus den Eingangsvariablen eine Vorhersage zu berechnen. Die Struktur des Netzes erlaubt es, sehr komplexe Funktionen zu approximieren. Die Kehrseite ist, dass neuronale Netze schwer zu interpretieren sind: Sie liefern Vorhersagen, aber sie erklären nicht, warum.
Die Qualität maschineller Lernverfahren hängt entscheidend von der Datenqualität ab. Das alte Prinzip gilt nach wie vor: Müll rein, Müll raus. Wenn die Trainingsdaten fehlerhaft, unvollständig oder nicht repräsentativ sind, werden auch die besten Algorithmen schlechte Ergebnisse liefern. Die Datenaufbereitung, also die Bereinigung und Strukturierung der Rohdaten, ist daher mindestens so wichtig wie die Wahl des Algorithmus.
Ein spezifisches Problem im Fußball ist die begrenzte Datenmenge. Im Vergleich zu anderen Anwendungsgebieten des maschinellen Lernens gibt es relativ wenige Spiele. Eine Bundesliga-Saison umfasst 306 Spiele, zehn Saisons also etwa 3000. Das klingt nach viel, aber für komplexe Modelle mit vielen Parametern ist es oft nicht genug. Die Gefahr des Overfittings, also der Überanpassung an die Trainingsdaten, ist daher allgegenwärtig.
Die Tücken der Statistik
Statistische Methoden sind mächtig, aber sie sind nicht unfehlbar. Es gibt systematische Fehlerquellen, die auch erfahrene Analysten in die Irre führen können.
Die Verwechslung von Korrelation und Kausalität ist ein Klassiker. Wenn zwei Variablen zusammenhängen, bedeutet das nicht, dass die eine die andere verursacht. Ein Beispiel: Mannschaften, die mehr Ecken haben, gewinnen im Durchschnitt häufiger. Aber die Ecken verursachen nicht den Sieg. Beides, Ecken und Siege, sind Konsequenzen einer dritten Variable, nämlich der Überlegenheit einer Mannschaft. Wer auf Ecken wettet, weil sie mit Siegen korrelieren, macht einen Denkfehler.
Das Overfitting ist ein weiteres Problem. Ein Modell kann die historischen Daten perfekt erklären, ohne dass es irgendetwas über die Zukunft sagt. Das passiert, wenn das Modell zu komplex ist und sich an zufällige Schwankungen in den Daten anpasst. Ein gutes Modell generalisiert, das heißt, es macht auch für neue, ungesehene Daten akkurate Vorhersagen. Die Unterscheidung zwischen echten Mustern und zufälligem Rauschen ist eine der größten Herausforderungen der statistischen Analyse.
Der Selection Bias betrifft die Auswahl der Daten. Wenn man nur Spiele analysiert, in denen ein bestimmtes Muster aufgetreten ist, überschätzt man die Bedeutung dieses Musters. Ein Beispiel: Angenommen, man untersucht nur Spiele, in denen der Außenseiter zur Halbzeit geführt hat. In diesen Spielen mag der Außenseiter oft gewonnen haben. Aber das liegt daran, dass die Stichprobe bereits auf untypische Spiele beschränkt wurde. Die Schlussfolgerung, dass Halbzeitführungen für Außenseiter besonders wertvoll sind, wäre übertrieben.
Die Illusion der Präzision ist eine subtile Falle. Wenn ein Modell eine Wahrscheinlichkeit von 67,3 Prozent ausgibt, suggeriert die Zahl eine Genauigkeit, die nicht vorhanden ist. Die Differenz zwischen 67 und 68 Prozent ist in der Praxis irrelevant, weil die Unsicherheit der Schätzung selbst viel größer ist. Gute Analysten kommunizieren ihre Ergebnisse daher mit angemessener Vorsicht und weisen auf die Grenzen der Genauigkeit hin.
Praktische Anwendung statistischer Methoden
Wer statistische Methoden für Fußballprognosen nutzen möchte, steht vor praktischen Fragen. Wie kommt man an die Daten? Welche Werkzeuge braucht man? Wie viel Aufwand ist nötig?
Die Datenbeschaffung ist heute einfacher als je zuvor. Kostenlose Quellen wie FBref bieten umfangreiche Statistiken für die großen Ligen, einschließlich Expected Goals und anderer fortgeschrittener Metriken. Für tiefere Analysen gibt es kommerzielle Anbieter wie StatsBomb oder Opta, die detailliertere Daten gegen Bezahlung liefern. Die Wahl hängt vom Budget und vom Anspruch ab.
Die Werkzeuge reichen von einfachen Tabellenkalkulationen bis zu spezialisierten Programmierumgebungen. Für grundlegende Analysen genügt Excel oder Google Sheets. Für komplexere Modelle sind Programmiersprachen wie Python oder R besser geeignet. Sie bieten Bibliotheken für statistische Analysen, maschinelles Lernen und Visualisierung, die weit über die Möglichkeiten von Tabellenkalkulationen hinausgehen.
Der Zeitaufwand hängt von den Ambitionen ab. Eine einfache Elo-basierte Prognose lässt sich in wenigen Stunden implementieren. Ein vollständiges Poisson-Modell mit allen relevanten Faktoren erfordert einige Tage Arbeit. Ein ausgereiftes Machine-Learning-System kann Wochen oder Monate in Anspruch nehmen, je nach Komplexität und verfügbarer Expertise.
Für die meisten Nutzer ist es sinnvoller, auf bestehende Dienste zurückzugreifen, als eigene Modelle zu entwickeln. Die kommerziellen Anbieter haben Zugang zu besseren Daten, mehr Rechenleistung und mehr Erfahrung. Der Mehrwert eines eigenen Modells liegt weniger in der Prognosequalität als im Verständnis, das man durch die Entwicklung gewinnt. Wer versteht, wie die Modelle funktionieren, kann die Ergebnisse besser einordnen und kritischer bewerten.

Die Integration verschiedener Methoden
Die besten Prognosesysteme kombinieren verschiedene statistische Ansätze. Kein einzelnes Modell ist für alle Situationen optimal, und die Kombination verschiedener Perspektiven kann die Gesamtgenauigkeit verbessern.
Ensemble-Methoden aggregieren die Vorhersagen mehrerer Modelle. Das kann so einfach sein wie der Durchschnitt der Vorhersagen oder so komplex wie eine gewichtete Kombination, bei der die Gewichte selbst optimiert werden. Die Grundidee ist, dass verschiedene Modelle unterschiedliche Fehler machen und diese Fehler sich teilweise ausgleichen, wenn man die Modelle kombiniert.
Die Hierarchie der Modelle ist ein weiterer Ansatz. Ein einfaches Modell wie Elo liefert eine Basisschätzung, die dann durch komplexere Modelle verfeinert wird. Die komplexeren Modelle korrigieren die Basisschätzung nach oben oder unten, je nachdem, ob sie zusätzliche Informationen haben, die die Basisschätzung nicht berücksichtigt.
Die menschliche Überprüfung bleibt wichtig. Kein statistisches Modell kann alle relevanten Informationen erfassen. Verletzungen, Konflikte in der Mannschaft, besondere Motivationslagen: Solche Faktoren sind oft nicht in den Daten enthalten, aber sie können Spiele entscheiden. Ein erfahrener Analyst kann die statistischen Prognosen durch sein Kontextwissen ergänzen und korrigieren.
Von Billy Beane bis zur modernen KI
Die Geschichte der statistischen Sportanalyse ist eng mit dem Namen Billy Beane verbunden. Der General Manager der Oakland Athletics revolutionierte in den frühen 2000er Jahren den Baseball, indem er sich auf statistische Analyse statt auf traditionelle Scouts verließ. Die Geschichte, verewigt im Buch und Film Moneyball, zeigte, dass datengetriebene Entscheidungen einen echten Wettbewerbsvorteil bringen können.
Im Fußball dauerte die Revolution länger. Der Sport ist komplexer als Baseball, mit mehr Spielern, mehr Interaktionen und weniger klar definierten Ereignissen. Aber ab den 2010er Jahren begannen die Vereine aufzuholen. Der FC Liverpool unter Jürgen Klopp wurde zu einem Vorreiter der datengetriebenen Spielerrekrutierung und Taktikanalyse. Der Erfolg sprach für sich und überzeugte auch skeptische Traditionalisten.
Heute ist die statistische Analyse im Profifußball Standard. Kein ambitionierter Verein kommt ohne Datenanalysten aus, und die Methoden werden immer ausgefeilter. Die Frage ist nicht mehr, ob Statistik hilft, sondern wie man sie am besten nutzt. Die KI-Revolution der letzten Jahre hat die Werkzeuge noch mächtiger gemacht, aber die Grundprinzipien bleiben dieselben: Daten sammeln, Muster erkennen, Vorhersagen treffen, aus Fehlern lernen.

Grenzen und realistische Erwartungen
Statistische Methoden sind mächtig, aber sie haben fundamentale Grenzen, die kein Algorithmus überwinden kann.
Die Unvorhersehbarkeit des Fußballs ist keine Schwäche der Modelle, sondern eine Eigenschaft des Sports. Ein Ball, der an den Pfosten geht, hätte auch einen Zentimeter weiter rechts ins Tor gehen können. Solche Mikroereignisse entscheiden Spiele, aber sie sind prinzipiell nicht vorhersagbar. Die besten Modelle können die Wahrscheinlichkeiten schätzen, aber das Ergebnis bleibt ungewiss.
Die Effizienz der Wettmärkte ist ein weiterer limitierender Faktor. Die Buchmacher haben Zugang zu denselben Daten und verwenden ähnliche Methoden. Wenn ein Muster leicht zu erkennen ist, ist es wahrscheinlich bereits in den Quoten eingepreist. Echte Value-Wetten zu finden, erfordert entweder bessere Daten, bessere Modelle oder schnellere Reaktion auf neue Informationen. Keines davon ist für den Privatanwender leicht zu erreichen.
Die psychologischen Fallen sind nicht zu unterschätzen. Die Verfügbarkeit statistischer Analysen kann zu übermäßigem Vertrauen führen. Wer glaubt, die Zukunft berechnen zu können, unterschätzt die Unsicherheit und überschätzt seine eigenen Fähigkeiten. Die Demut vor dem Zufall ist eine wichtige Tugend, die auch die besten Statistiker nie vergessen sollten.
Verantwortungsvoller Umgang mit Statistik
Statistische Fußballanalysen sind ein Werkzeug, kein Wundermittel. Sie können helfen, bessere Entscheidungen zu treffen, aber sie können die grundsätzlichen Risiken des Wettens nicht eliminieren.
Wer wettet, sollte die Statistik als Informationsquelle nutzen, nicht als Orakel. Die Zahlen liefern Orientierung, aber sie treffen keine Entscheidungen. Die Verantwortung bleibt beim Menschen, und sie umfasst mehr als nur die Prognosequalität. Wie viel kann ich mir leisten zu verlieren? Wie gehe ich mit Niederlagen um? Wann ist es Zeit aufzuhören? Diese Fragen kann keine Statistik beantworten.
Die Transparenz der eigenen Methoden ist wichtig. Wer seine Entscheidungen auf Statistik stützt, sollte verstehen, welche Annahmen in die Berechnungen eingehen und wo die Grenzen liegen. Blindes Vertrauen in Zahlen ist gefährlich, weil es die kritische Reflexion ausschaltet. Die Geschichte kennt genug Beispiele von Modellen, die unter bestimmten Bedingungen versagt haben, weil ihre Annahmen nicht mehr zutrafen.
Schließlich sollte der Spaß am Spiel nicht verloren gehen. Fußball ist mehr als eine Rechenaufgabe. Die Spannung, die Überraschungen, die Emotionen: All das macht den Sport aus und sollte durch keine Statistik ersetzt werden. Die Zahlen sind eine Ergänzung, keine Alternative zum Erlebnis. Wer das beherzigt, wird mit statistischen Fußballanalysen mehr Freude haben als jemand, der nur noch in Wahrscheinlichkeiten denkt.